SQL or NoSQL
Ujjawal Sidhpura
11 Feb 2022
•
4 min read
Introduction
Every programmer at some point in their career or learning curve wonders about this existential question- which database to choose:SQL or NoSQL. Which one is better? List of factors affecting this choice is long, pretty long. And even if you luckily come up with an answer, then comes the next question as to which database program to choose for your chosen database structure.
History
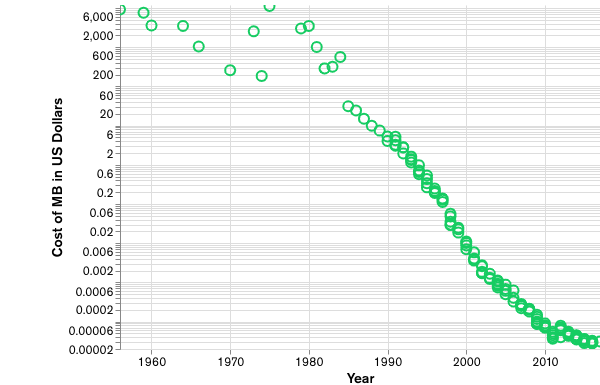
Let’s go over the history quickly to get a quick glimpse. Data is the most valuable commodity in today’s world. In fact, this was understood very early since the arrival of computers in later part of 20th century. Relational database model was introduced in 1970s and it became an instant hit. Prime motto of RDBMS is to reduce data duplication and back in the 70s, that was a big thing. Data storage was expensive and infrastructure wasn’t that developed to efficiently store the massive influx of data. But then internet (or www as we may say) started growing exponentially. This create huge amount of data. And with more and more web applications, need to quickly create and access enormous data became more important. This is when NoSQL came in to rescue. At this point in late 2000s, cost of data storage or infrastructure wasn’t an issue.
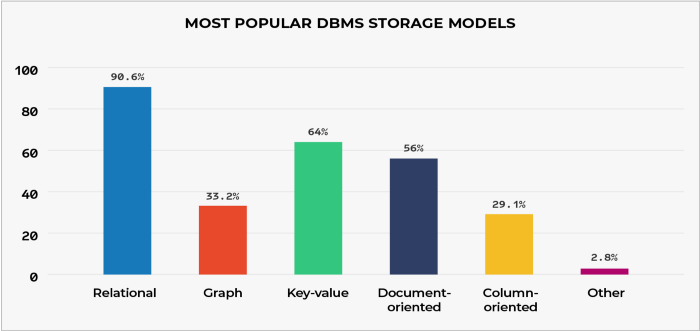
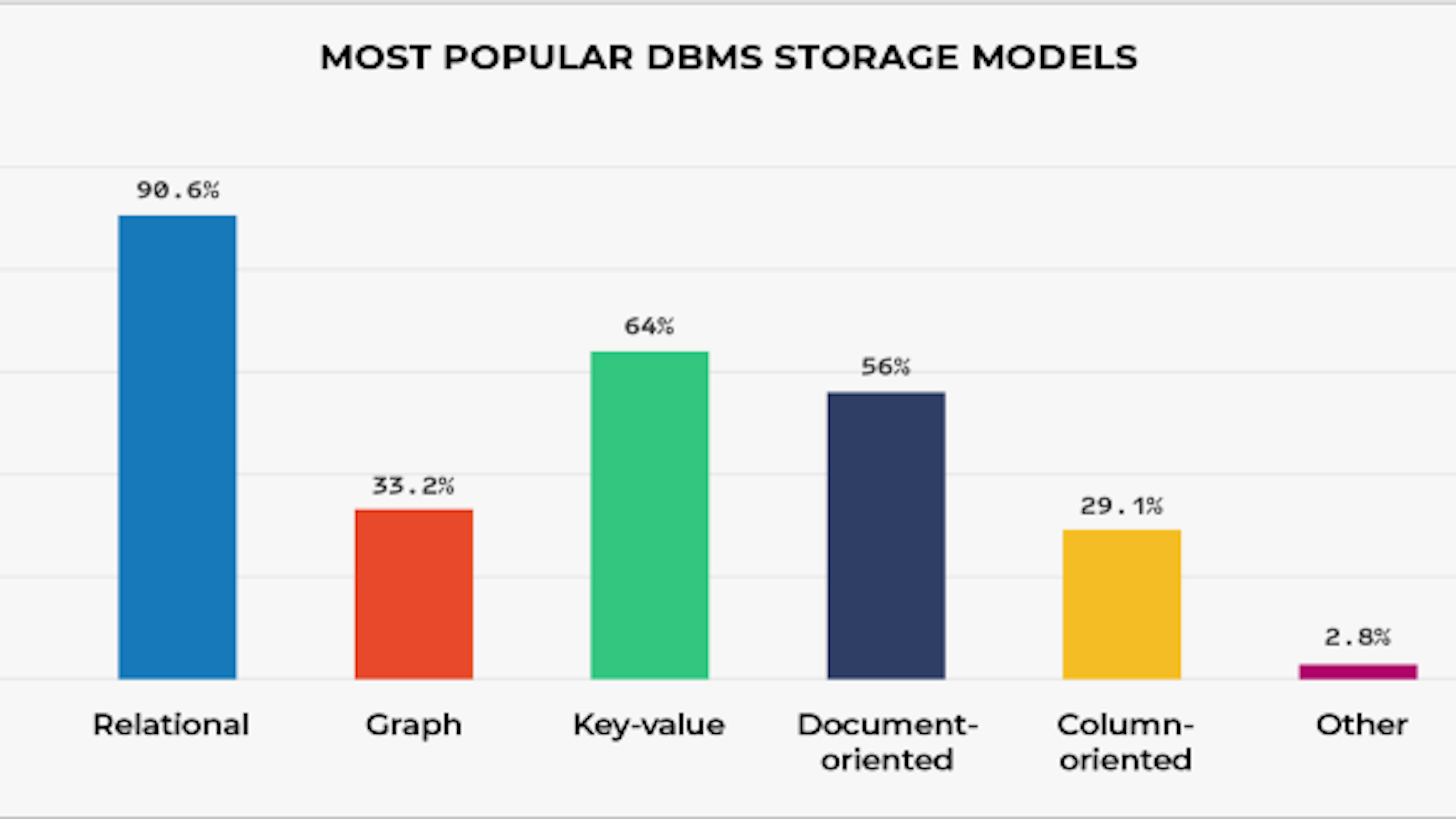
As per this report in 2017, NoSQL database system are more popular and in use than RDBMS. let’s go through basic highlights and differences of SQL and NoSQL
Querying Language & Database Schema
SQL: SQL database use structured query language. They have pre-defined schema for data structure. SQL querying languages have been around for long time and have evolved greatly , even providing with great libraries one can use to ease querying. It is perfect for complex data structures and queries. But SQL has strict data structure. SQL query language is declarative and lightweight. Significant research has to be done before creating and implementing any RDB since it is very difficult to change schema and data structure once project is deployed.
NoSQL: NoSQL have dynamic schema and hence data can be created quickly without defining the structure. Every document can have it’s own structure and syntax, and there is flexibility to use column-oriented, document-oriented, graph-oriented or Key-value pairs! Each NoSQL can have a different query language, adding to the complexity of learning more languages in order to work with different database. NoSQL query language is non-declarative.
Data Structure
SQL: Data is stored in tables with pre defined columns. Each entry is a new row essentially that we are creating or accessing. NoSQL: Data can be stored as a JSON, graph, key-value pairs or tables with dynamic columns.
Database Scaling
SQL: They are Vertically scalable. Load handling capabilities of a single server can be increased by adding more RAM, CPU or SSD capacity. This is also called ‘scale-up’.
NoSQL: They are Horizontally scalable. Data traffic can be increased by sharding, simply by adding more servers. They are better from scalability perspective, and preferred for large and frequently changed data.
Sharding is the process of breaking up large data into smaller chunks and spread across multiple servers.
Database Transaction
SQL : SQL follows ACID
NoSQL: NoSQL follows BASE
Quick Overview
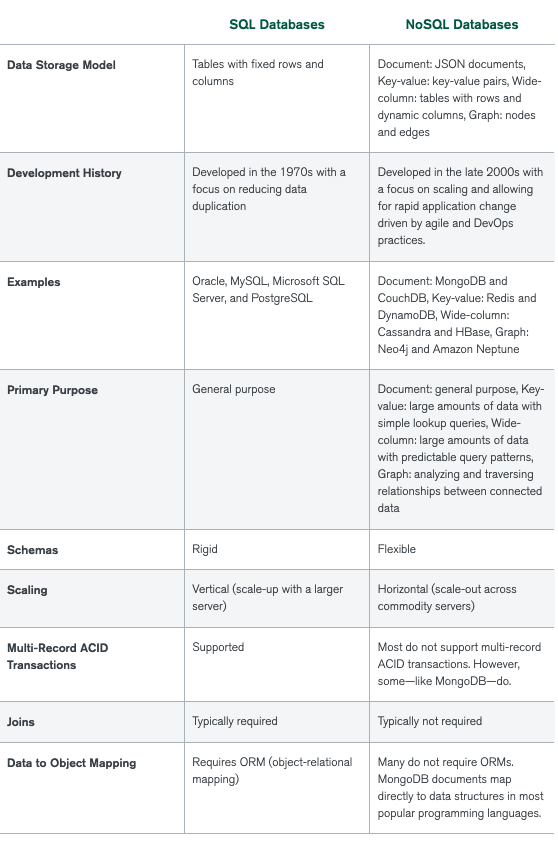
This leave us with lots of options.
SQL: MySQL, PostgreSQL, Oracle, Microsoft SQL…..
NoSQL : MongoDB, Apache Cassandra , Google BigTable, Apache HBase…
Making a choice for the right database
For starters, there is never The Only right way. There will always be many. To each their own; as they say. But even before we start to decide between SQL and NoSQL, we have to focus on 3 core concepts for our database that suits our project.
Structure: Every project needs to store and retrieve data differently. Structure needs to be chose that requires least amount of work and easy scalability.
Speed and Scale: Data modelling can help in deciding best route to get optimum speed. Some databases are designed for optimized read-heavy app while others write-heavy solutions. Selecting right database for project’s I/O is important.
Size: It depends on maximum amount of data we can store and process, before impacting the database. It can vary from combination of data structure stored, partitioned data across multiple filesystems and servers, and also vendor specifics.
Data Modelling
Data modelling is one of the most important process for selection of database and data structure. Data modelling makes it easier for developers , data architects and business analysts to view and understand relationships among the data in database. This leads to a proper project structure and less issues in future.
Data modelling is process of creating a visual representation of types of data used and stored within the system, relationship among these data types, the ways data can be grouped and organized and its formats and attributes.
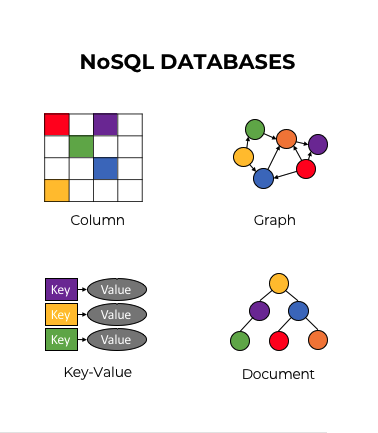
Mixing Database Types
Modelling process helps us understand project needs. And sometimes we may end up using both types of databases in our project. When selecting more than one database, it is important to select one database that will own specific set of data i.e. use canonical data model. Each database is the owner of its data, which can be shared with other databases. Canonical data models are a type of data model that aims to present data entities and relationships in the simplest possible form in order to integrate processes across various systems and databases.
To sum up…
Understand the Data structure your project require, the amount of data to be stored/retrieved, anticipate long term future needs and scalability, cost of upgrades and maintenance, use data model to determine if you database is relational, document, columnar, key-value pair, graph or combination of either-or. It is also useful to read documentation of few famous databases around.
Ujjawal Sidhpura
My name is Ujjawal or better let's go with my anglicized name Ujay. I am a Full-stack Developer who reinvented his career, jumping from a 6-year career in Civil Engineering/Facility Management into the wild wild world of coding. I love working with PERN/MERN stack. My favourite scripting language is JS, but I can also code in Ruby, Python and TS if I have to, woot woot. Apart from coding and making real-life projects, I love to run, bike, yoga (cliche huh), netflixing(if that's even a word). I am a coffee connoisseur who likes to explore different coffee joints and do extended coding sessions under the influence of caffeine.
See other articles by Ujjawal

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!